Personal weblog of Ted Pavlic. Includes lots of MATLAB and LaTeX (computer typesetting) tips along with commentary on all things engineering and some things not. An endless effort to keep it on the simplex.
There are a few times every year when faculty members are bombarded with requests to write letters of recommendation for students. Sadly, we do not do a good job telling undergraduate students what kinds of relationships they should be building with faculty to ensure that when the time comes (e.g., applying for graduate school or medical school), there will be two or three different faculty who feel comfortable writing a recommendation letter.
A good recommendation letter must do much more than just verifying a grade in a class. Students applying for graduate school will be asked to submit verified transcripts, and so the veracity of reported grades will not be in question. Furthermore, if all a letter writer can do is verify a grade in a course, then that actually speaks negatively for the student because it indicates that the student could not find a letter writer who could supply a stronger message. In fact, some of the best letters are from faculty who can address why an admissions committee should overlook a low GPA or a poor grade. The best letters are not about grades, they are about people.
Students should keep in mind that every person that they ask to write them a letter will be given a form like the one below and an opportunity (which is expected that they will take) to write a 1–2 page free response reflecting on the student and their potential for the program for which they are applying.
Example questions from an actual recommendation letter form for a graduate school application (click to expand)
Although the forms for each graduate program have slightly different questions, they all ask questions very similar to the ones above. If a student asks me for a letter, and I have never had an office-hours conversation with the student before (let alone exchanged an e-mail), it would be very difficult for me to attempt an answer to any of those questions above. At a minimum, I need to understand a student’s career goals and motivations for graduate study. It is ideal if I have worked with the student on a project (e.g., undergraduate research), but often just one or two good conversations during office hours is enough for me to attempt answers to the questions above and even write a one-page letter that does much more than just confirm the reported grade for my course.
So, choose wisely when picking letter writers. The best letters are going to be very personal and specific to your case and will address any parts of your application that you think might make you look weaker than other candidates (e.g., a low GPA or low grades). How do you make sure you will be able to pick a good letter writer? Start early. If you have time, try to get involved in some projects with faculty so that they have experience working directly with you. But even if you can’t do that, just go to office hours and chat with the faculty member about your career goals. Ask questions about graduate school, and maybe you’ll learn something interesting.
If you didn’t know to do this during your undergraduate degree, it’s not too late to schedule a meeting with one of your old professors. Tell them that you are considering graduate school and wanted to ask a few questions and get their reflections about your chosen career path. Just ten or fifteen minutes in conversation is enough to turn a recommendation letter into something that looks like it was written by a robot to something that will go a long way to getting you passed the admissions committee.
I think most anyone who has heard of a robotic vacuum cleaner has heard of the industry leader, iRobot. However, I've noticed that the offerings from iRobot have stagnated a bit and lag behind innovations at their competitors. One such competitor is Ecovacs. During COVID-19, my wife and I decided to add a new puppy (Dexter, cream-colored Golden Mountain Doodle pictured near the bottom of page) to our home after our old dog (Fritz, black-and-white Cock-a-chon pictured at very bottom) sadly passed on. Dexter has been wonderful, but his new limber legs and light shedding has meant more fur and leaves (we have a dog door) collecting each day. So we decided to check out the robo-vacuum market. As a control engineering/AI researcher myself, I was impressed to see vSLAM on most robots mid-range and higher, with some of the non-iRobot varieties incorporating other technology that is awesome to see transferred out of the research laboratory. Here, I take a look at the vacuum we ended up getting (after trying the iRobot version and returning it due to incompatibilities between it and our carpet and a lack of state-of-the-art features).
As you can see below, after every vacuuming session, I get a report of where the robot has been and what obstacles it has encountered (so I can go and clean them up). In fact, I can even view it moving around on the map in real time while I'm away. Although iRobot models do multi-floor mapping (like this one), you have to wait to interact with the map afterward (and you cannot see exactly where the robot has been and what route it took). The Ecovacs models allow you to pause the robot in the middle of a session and add virtual barriers and no-go zones.
We set our vacuum to run every night downstairs at 2am, and we have a Hubitat Elevation Hub that ensures that the lights come on then to aid in the navigation of the robot (and turn off after it is done). So far, this has not caused any problems for us (or the dog) sleeping. When it finishes (1100 sq. ft. in about 65–90 minutes), it returns to the auto-empty station and empties its dust bin automatically. We then get told when to change the bag in the station. The nice thing about having to buy the auto-empty station separately is that it means I have a spare charger (that came with the main unit). So I've set that up upstairs. Then, on Saturday mornings, when we take puppy Dexter to training, I place the robot on its spare charger upstairs and let it go. It recognizes that it has been moved to another floor and vacuums according to that map (you can load up to two maps). When we get home, I carry it back downstairs, place it on the auto-empty station, and tell it to empty the dust bin (which would have been done automatically if it had docked in the auto-empty station as it does every night).
The Vacuum also has mopping features built in (if you load it up with water and the mopping pad), and there is an additional extension that you can buy that adds ultra-sonic scrubbing to the mop. I understand the potential downside to that is that it isn't always able to get docked when that attachment is connected. That was OK with us because we really got it to pick up fur, Arizona dust, and leaves brought in by the dog (through his dog door). It works well for that, and it adjusts its thrust depending on the surface it is on (we have carpet and tile) and resistance it feels. So we ended up not buying the extra mopping unit (but might someday try the mopping features of the base unit).
There are some geeky additional non-vacuuming features too. The camera (which faces forward and thus is not useful when the bot is docked) can be viewed from remote, and the bot can be driven around as well. You can even set it into "patrol mode" where it moves around and takes video and stores that video for later viewing. If you manually connect and drive it around, you can actually engage its speaker so you can, for example, talk to your dog while you're away.
You can cover up the camera (they give you an attachment for that, which is a little clunky) in case you are worried about privacy. Like most of these super-smart vacuums, it capitalizes on access to the camera for navigation ("vSLAM"). In other words, despite having LIDAR to find obstacles, it fuses both of them. So covering the camera makes mapping and navigation less efficient. Furthermore, it is best for it to vacuum in at least dim light, which is why I ensure the lights come on while it is vacuuming (as described above).
Recently, my university has changed things so that faculty using Canvas LMS will now encounter the “Enhanced Rich Content Editor (RCE)” by default whenever they edit an assignment, announcement, etc. Strangely, this change was made in the middle of the semester, not giving faculty who were unfamiliar with the "Enhanced" RCE a chance to find everything they frequently used in the classical editor. So here's a list of tips (with screenshots) to help you get used to the new editor.
ASU uses MediaAmp to host videos for streaming to students. If you’re looking for MediaAmp (to embed videos) in the new RCE, you have to click on the little “Plug-in” icon (looks like a plug) and possibly search for it under “View All.”
If you’re looking for course links (Pages, Assignments, etc.), you have to click on the “Link” Icon (looks like chain links) and then select “Course Links."
If you’re looking for your Files, you have to click on the “Link” icon, then select “Course Links”, then in the pop-up “Add” window that comes up on the right, change “Course Links” to “Files."
Alternatively, some of you might not see the wisdom of changing editors in the middle of a semester like this one. For those of you, you can go to “Settings” and “Feature Options” and then toggle “RCE Enhancements” OFF to get the old editor back (at least for a little while).
I hope that's helpful! I wish I could say that the Enhanced RCE is an improvement, but I think you can see how it adds so many extra steps to find things that used to be up front and ready to use in the old editor. Even though it looks a little nicer, it's a net downgrade from the old editor. And it is still impossible to drag images into the editor to insert them or simply paste them in place. You get no functional benefits out of the editor, and you get a lot of extra drag.
A guide to the three pressures that shape innovation in living and non-living systems.
(a version of this article has also been posted to Medium)
I teach a course on Bio-Inspired AI and Optimization that is meant to be a graduate-level survey of nature-inspired algorithms that also provides a more serious background in the natural-science (primarily biological) fundamentals underlying the inspiration. The first half of the course covers nature-inspired optimization metaheuristics, with a heavy focus on evolutionary algorithms. An evolutionary algorithm is a scheme for automating the process of goal-directed discovery to allow computers to find innovative solutions to complex problems. There is a wide range of evolutionary algorithms, but a common feature of each is that the computer generates a population of random candidate solutions, evaluates the performance of each of these candidates, and then uses the best of these candidates as “parents” to guide the generation of new candidates in the next generation.
Most of my students come from computer science or engineering backgrounds and, as such, have very little formal education in biology let alone something as specific as population genetics (“popgen”). However, to really understand the complex process of evolutionary innovation inherent to evolutionary algorithms (and evolutionary computing in general), it requires at least some fundamental background in popgen. I think when most people reflect back on their high-school biology courses, they might remember something about natural selection and mutation being important in thinking about the evolution of adaptations in natural populations. However, there is a third evolutionary force that is extremely important — especially when considering small populations, like the ones that are artificially generated in an evolutionary algorithm. That force is (genetic) drift. So let’s review all three:
Natural selection reflects that some individuals in a population will be at a fundamental disadvantage with respect to other individuals. Those individuals (who are, in the computational creativity context, are relatively poor solutions to a problem) will be very likely to be “selected out” in large populations because there will be so many other individuals who are relatively “fitter.” “Fitness” is a measure of how many offspring an individual can put into the next generation given the current context. If some individuals can put more individuals into the next generation than others, they are “more fit.” If all individuals have the same fitness, then every parent has the same chance of getting her offspring into the next generation. If some individuals have less fitness than others, then they have less chance of getting their offspring into the next generation.
Some people are taught that natural selection only matters when resources are scarce and thus population sizes are limited (thus making individuals compete for opportunities). This is not the whole story and is why we must discuss (genetic) drift below. Before getting into that, note that even in populations that are not limited, differences in the rates of growth of different strategies will gradually change the relative share a strategy has of a population. So even without resource limitation, differences in “relative fitness” will naturally select for the most fit individuals to have the strongest share of the population.
By itself, selection can only tune the relative proportions that different strategies have in a population. However, many evolutionary processes have a way of blending from different parents to create offspring that somehow interpolate from those parents. In biology, we view “sex” as the primary way in which we see “recombination” of strategies. There are sex-like mechanisms in evolutionary algorithms that do the same. So when natural selection is combined with recombination (“sex”), we get optimization combined with a little bit of goal-directed novelty generation. However, recombining strategies across different parents can deleterious because breaking up two functional strategies and putting them together does not guarantee that the result will itself be functional. Those strategies that result that are functional might improve upon both parents, but the novelty may be limited because it simply borrows from strategies of the parents.
Mutation is one way to introduce novelty that can be tuned to be less disruptive as recombination while also producing more novel solutions than recombining solutions from the parent generation. In mutation, random changes in a parent strategy are introduced. In a population of clones of a single strategy, mutation introduces novel variations that generates differences in offspring that hopefully lead to differences in relative fitness. These fitness differences will cause some mutations to grow in representation and others to shrink in representation. So one of the functions of drift is exploration to find new candidate solutions that might be better than anything in the current population. However, another important function of mutation is to balance the stagnating force of genetic drift.
(Genetic) Drift is a subtle but extremely important evolutionary pressure that represents what occurs when population sizes eventually meet their limits. As mentioned above, in a world of plentiful resources, natural selection will allow every strategy to survive and produce offspring, but strategies that produce more offspring will grow in their share of the total population. Eventually, if the population is very large and becomes limited in how much it can grow, those strategies that have a lot of representation will have a much higher probability of being represented after the limitation kicks in. In other words, when population sizes are high, resource limitation is a culling effect—strategies that are more fit tend to be selected to continue and strategies that are less fit are “selected out” and removed. However, this culling effect eventually leads to its own demise as the removal of low-fitness individuals also results in the removal of diversity which is required for natural selection to work. As mentioned above, the action of natural selection only optimizes among the diversity of solutions in the parent generation. If the parent generation has no diversity, then there are no improvements that natural selection can make. When a population finds itself full of identical individuals and thus stuck and unable to generate any new novelty, we refer to that population as being “fixed” or having reached “fixation.” Genetic drift represents this gradual march toward fixation. Natural selection, when combined with population limitation, is always being pulled toward fixation where natural selection will fail to be able to act.
Fortunately, mutation (mentioned above) can rescue us from drift. Mutation introduces new variation in a population, and natural selection can choose strategies out of that new variation. So if we want to combat drift, we can just crank up the mutation rate. The downside of that is that the mutation rate also quickly corrupts well-performing strategies. So populations that have a high mutation rate will tend to have a diverse set of strategies within them and maintain a diverse set of fitnesses. Some individuals will have very high fitness, but they will co-exist with individuals with very low fitness (due to mutation) that are just a side effect of the stabilizing force of mutation. Reducing the mutation rate helps to ensure all solutions have similar fitness, but there is never any way to know if a population of individuals with similar fitness is because their shared strategy is good or they simply reached fixation too soon.
The problem of reaching fixation “too soon” is particularly strong for small population sizes. In a small population size, small differences in fitness may fail to generate sufficient selective pressure to dominate the force of genetic drift. For example, in a population that is limited to a size of 10, an individual with a fitness 1/100 of some other individual may still by “good luck” produce a single offspring in the next generation. That offspring, although 1/100'th as fit of a strategy as some other in the population, nevertheless takes up 10% of the next generation. So for small population sizes, mutation and drift are essentially the only drivers of evolution.
So when building an evolutionary algorithm, it is important to start with a diverse population and then build mutation and selection operations that maintain diversity as long as possible (staving off genetic drift). So long as the population is diverse, natural selection will continue to explore large regions of the strategy space. However, if mutation is too strong, then it will limit exploitation and tuning of strategies because adaptations that make small changes in fitness will quickly be lost to mutation. Consequently, if you have the computational budget, it is best to build very large population sizes with very low mutation rates and choose selection operators that moderate selection pressure — giving low-fitness strategies a chance to stay in the large population pool.
Similarly, when thinking about evolution in natural systems, it is important to remember how large the ancestral populations were. Those that evolved in large-population contexts may tend to show more signs of natural selection (and will likely have evolved mechanisms to reduce the mutation rate). Those that evolved in small-population contexts may tend to have high mutation rates and show diversity patterns more closely related to randomness. This latter case relates to neutral theories of evolution, which are important to consider when trying to understand the source of observed variation in systems we see today.
This story is summarized in the graphic I’ve prepared above, which shows mutation and natural selection as forces re-shaping populations within a drift field that, in the absence of those forces, will eventually homogenize the population on an arbitrary strategy.
So how do we come up with interesting new ideas for mutation and selection operators for evolutionary algorithms? We should continue to look at population genetics. In fact, some theories in population genetics (like Sewall Wright’s shifting-balance theory) are much better descriptors of evolutionary algorithm behavior than the more complex evolutionary trajectories of living systems. For example, distributed genetic algorithms, which create islands of evolutionary algorithms that only exchange population members across island boundaries infrequently, tend to out-perform conventional genetic algorithms on the same computational budgets for reasons that make sense in light of population genetics. This is a more advanced topic, and you’re welcome to read/listen more about this in my CSE/IEE 598 lectures. For now, I hope you look at living and non-living populations around you through the lenses of mutation, drift, and natural selection.
There's nothing worse than bad lighting on a video call or while recording a video. Experts will tell you that you should buy a nice ring light, which provides a nice diffuse glow on your face as you record. However, most ring lights are eyesores on a modern desk and are generally pretty inconvenient, especially if you regularly use a laptop as your recording rig. For example, a good quality ring lamp might require clamping onto the edge of a desk, which might not be ideal for your desk setup. Fortunately, I've found a cheap solution (far cheaper than most ring lights) that does a great job, is super portable, and looks great on a desk.
It is cheap (at the time of this post, it is $16.99 on Amazon and has an additional 10% coupon that can be applied), and it has an array of features that are great for any Zoom call or camera session in general. For example:
3 Lighting Modes (5000K, 4000K, and 3500K – pick your color temperatures for your complexion and camera)
Continuously dimmable (800 lumens max)
Diffuse disc of LED light (not a point source)
Flexible gooseneck and weighted base allows for tipping up to vertical
Uses a rechargeable battery, and so:
It can be plugged in continuously
It can be unplugged and moved for the best lighting experience (very portable!)
I don't know how long this little thing will last, but it seems pretty sturdy. My wife has an older version of what appears to be the same OEM product, and it is still going. I have several colleagues who have purchased this one after my recommendation, and they tell me it's working great for them.
I hate submission comments in Canvas LMS. Students are given the impression that these are nice ways to send questions or comments to the instructor, but they are too easy to overlook. For example, the Canvas Teacher mobile app will send a notification whenever a student leaves a submission comment, but the notification text is often truncated and so it is impossible to see which assignment was commented on (even if the student commenting is clear). Furthermore, if you activate the notification, Canvas Teacher brings you to the dashboard as opposed to the comment itself and the notification is lost forever.
Today I discovered that in the "Inbox", which otherwise is for Canvas e-mails, there is the additional functionality to see ALL SUBMISSION COMMENTS across ALL COURSES in one place! Simply click on the "Inbox" and then go to the drop down box in the top left and select "Submission Comments" (as shown below). You can then review all recent submission comments and reply to them without even revisiting the assignment.
So now when I get a notification about a submission comment, I go directly to the Inbox rather than trying to hunt through all assignments (and eventually giving up).
There is a beta feature in Zoom (version 5.2.0 and higher) that is easy to miss but can make for a slightly more exciting way to share slides. When sharing your screen, try clicking on the "Advanced" tab (top center) to reveal several useful options:
There is a beta feature, "Slides as Virtual Background," that lets you choose a slide presentation. Sadly, it only supports PowerPoint presentations at the moment. This is strange because it first converts the PPTX to a PDF and then displays the PDF instead (which means your animations and slide transitions will be removed). So it seems like they should be able to support a PDF directly. I am hoping that will be added in the future.
Once you select a presentation, it will display behind you. It shows you a slide advancer (to move through your presentation). It also allows you to move yourself around the slide and re-scale your size. You can do this live, which lets you place yourself next to important features of the slide (or move yourself off of important features). By default, it scales you down and puts you in the bottom right corner.
Again, this will be much nicer when it supports PDF's in general (as opposed to just PPTX).
CAVEAT ABOUT RECORDINGS: For now, the merged video (showing speaker on top of slides) will only record if you select to record locally. Cloud recordings will capture the unmerged view. I suspect that eventually they will implement this feature in their cloud backend and the merged view will be able to be seen there too. However, at least for now, if you do this and want it recorded, make sure that you record locally.
“Voting should take some effort. It means more that way.”
This was a statement I copied from a social media post of an old acquaintance, but I have heard the same sentiment from many others. They say that voting is important, perhaps the most important assertion of someones feelings that they can make, and so a certain amount of inconvenience is necessary to adequately motivate someone to deliberate on important options and make an informed choice. This logic usually then takes a leap and leads to the conclusion that all voting should be in person; mail-in voting is “too easy” to encourage people to make good choices.
However, the danger of using in-person voting as an explicit barrier to entry to filter out those who do not “care enough” about voting is that the burden of in-person voting is not the same across an entire population. Thus, accepting in-person voting as the mechanism that imposes costs (and requires effort) is an implicit statement that some votes are less valuable than others not because the voter cares less but because the voter happens to be more burdened by the process of in-person voting. But voting is meant to be a vehicle for those who will be affected by government actions to have a voice in deciding who will make up the government that takes those actions. Those who are the most burdened by lack of infrastructure, for example, should certainly not be attenuated; if anything, their voices should be amplified.
Furthermore, it is false to suggest that voting by mail is far easier than voting in person. Voting by mail requires considerable deliberation, care, and effort to complete. Just because someone receives a ballot in the mail (which they may have had to go through a process to register to receive) does not mean that they will open it, complete it (perhaps bubbling in tens to hundreds of bubbles), package it properly to return, and deposit to a mailbox. You could argue that if someone lives next to a polling location, it would be much easier to wander in and vote electronically with little deliberation (just tapping randomly on a screen) than it would be to actually fill out and return a mail-in ballot properly. In fact, if we were to abolish in-person voting entirely so that everyone would have to vote by mail, my guess is that many voters who found in-person voting very convenient might start skipping some elections because they couldn’t be bothered with the longer process of mail-in voting.
And that’s the big point — asymmetries of convenience create biased voting demographics. The issue is not that voting by mail is “so convenient” (because it isn’t!); it is that voting in person is, for some, prohibitively inconvenient. There should be a space for both kinds of voting (and possibly more). If we really want a representative sample of a population, we have to ensure our sampling methods do not inadvertently (or otherwise) exclude parts of the population that will be affected by the outcome of the process of voting that they were excluded from.
If you really do want voting to “take some effort”, it should be motivational effort that is equally applicable to everyone and not physical effort that varies from person to person or community to community. Where do we get that motivational-effort barrier? From very large numbers of people voting. If large numbers of people vote, then each person feels that their vote is inconsequential, and so the costs of voting will always be larger than the benefits. This surplus in the costs of voting will always present a motivational barrier, and the size of that barrier will be similar across the large population of voters. Thus, magnifying the costs of voting is best accomplished by magnifying the number of people voting; it is poorly accomplished by magnifying the physical distance between some voters and their voting location.
An epidemic is not a single number. Knowing exactly how bad an epidemic is requires knowing both how quickly it is going to spread and how bad its effects will be on those who are affected by it. To make matters worse, parameters that characterize each of these separate factors usually cannot simply be “multiplied together” to understand their composed effects. They have to be filtered through dynamical models that properly account for depletion and saturation effects in populations. So it is understandable that the average person might have a hard time making sense of CDC estimates of such parameters, and it is not surprising that there are a lot of misconceptions and misperceptions about these topics.
Let’s take the CDC COVID-19 Pandemic Planning Scenario report (as of May 20, 2020). This looks like a simple document at first, but it may be difficult to understand how to pull all of these numbers together. For a variety of reasons, parameters of interest to epidemiologists are difficult to estimate from data. One method to mitigate issues with incomplete or noisy data is to make assumptions that help fill in the gaps, but then your analysis is only as good as your assumptions. To be conservative and to understand how sensitive predictions are to these assumptions, the CDC has come up with five different “scenarios” that stretch across a wide range of assumptions. To keep things simple, we will focus on “Scenario 5: Current Best Estimate”, which is the CDC’s best guess at where these epidemiological parameters are.
It is best to start with everyone’s favorite epidemiological parameter, R0. This is the so-called “basic reproduction number.” It is a measure of how fast a contagious infection can spread. R0 is the combination of three factors:
The rate of interaction between an infectious (contagious) person and others in the population (referred to as “contact rate” below in some places)
The probability that an infectious person will infect someone that they come in contact with
How long an infectious person stays infectious (we assume that after this period, they are in a permanent recovered state where they are immune to further infection)
Essentially, R0 is a ratio of the rate that an infectious person infects others to the rate that an infectious person becomes well. This ratio can be interpreted as the number of people an infectious person infects before they themselves stop being infectious. If R0 is less than 1, then a disease will naturally die out because (on average) those infected will not be able to infect someone else before they become well. If R0 is greater than 1, then we have a so-called endemic. That means that the infectious disease will be constantly maintained at some background level; some fraction of the population will always be either currently infectious or recovered. Interestingly, this fraction is not 100%. As an infectious disease spreads through a population, the number of those who are susceptible to further infection declines to a point where it is rare for infectious individuals to encounter them (contacts with infected and recovered are far more common). This means that when susceptible individuals are rare, each infectious individual spreads less of the infection during the time window that they are infectious. This is the so-called herd immunity. A fraction of the population can stably remain susceptible because they are protected by the large numbers of others who have already had the disease and buffer them against contact with those who are currently infectious. The fraction of the population that will remain susceptible at the so-called endemic equilibrium is 1/R0. Likewise, the fraction of those in a population that must have been infected (or vaccinated, if possible) in order to achieve herd immunity is (1–1/R0). I should note that this simplified model assumes that infectious people eventually become recovered and stay that way; things get more complicated if immunity is not long lasting.
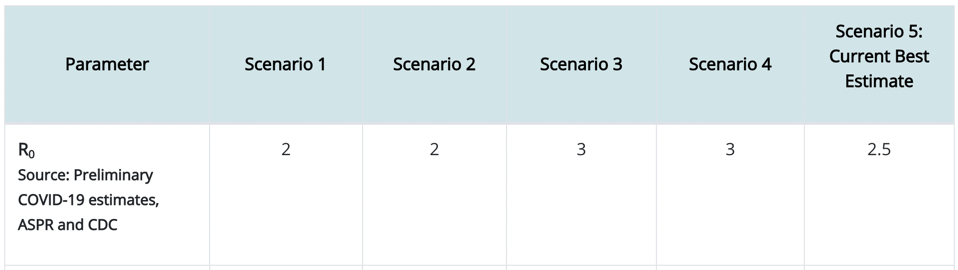
So what does the endemic equilibrium (“herd immunity”) look like for COVID-19 (assuming long-lasting immunity)? Here is what CDC estimates for R0.
Again, focusing only on Scenario 5, we take R0=2.5, which means that any infectious person will have an opportunity to infect 2.5 other people on average. So we then estimate that 1/R0=1/2.5=40% of the population will be able to avoid infection so long as the other 60% of the population goes through an infection or is vaccinated. So exactly how many people is that? In the United States, the population is a little over 325 million people (compare this to the world population of 7.8 billion people). So that means that 60% of the 325M people in the USA must be infected to achieve herd immunity. That’s 195M people in the USA (4.68 billion people worldwide).
But not everyone who is infected sees symptoms let alone has to go to a hospital or suffers an early death. If we go back to the CDC data, we see that…
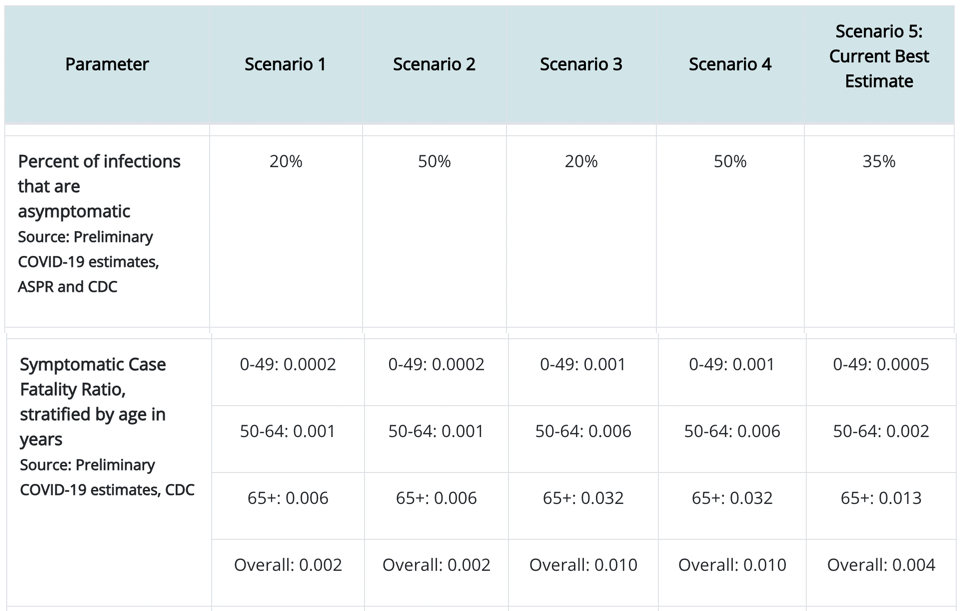
CDC estimates for asymptotic ratio and symptomatic case fatality ratio for COVID-19
Again, looking at Scenario 5, we see that 35% of those who have an infection show no symptoms. We also see that those other 65% who show symptoms will suffer fatality at an overall (averaged across age groups) rate of 0.004 (i.e., 0.4%). That seems like a very small number! But we have to keep in mind that this is a very contagious disease (any infectious person infects 2.5 other people). So we need to combine the information on contagion with the information on case fatality rate. For the 325M people in the USA, we already calculated that 195M will have the disease. So then, at the endemic equilibrium (“herd immunity”):
195M*65% = 127M people will have shown symptoms in the USA
127M*0.4% = 508,000 people will die in the USA
And worldwide, we would expect 12.2M people will die. So even at that very small case fatality rate, there will be a lot of death (and even those that escape symptoms may still feel long-term effects of COVID-19 that we are only starting to understand now). Just as a reference, 38,000 people died in car accidents in 2018 in the USA. We try to prevent deaths by car accidents by preventing car accidents and trying to make cars safe so that people will survive accidents that happen. When we ask people to wear masks and social distance, this is not unlike people’s legal obligation to wear seatbelts and drive cars that meet safety standards.
Now, a lot of people say that there is no way to prevent these deaths, and so it is better to suffer them early instead of dragging out our march to the endemic equilibrium. In order to evaluate whether this is a good argument, we should take a look at another part of the CDC data:
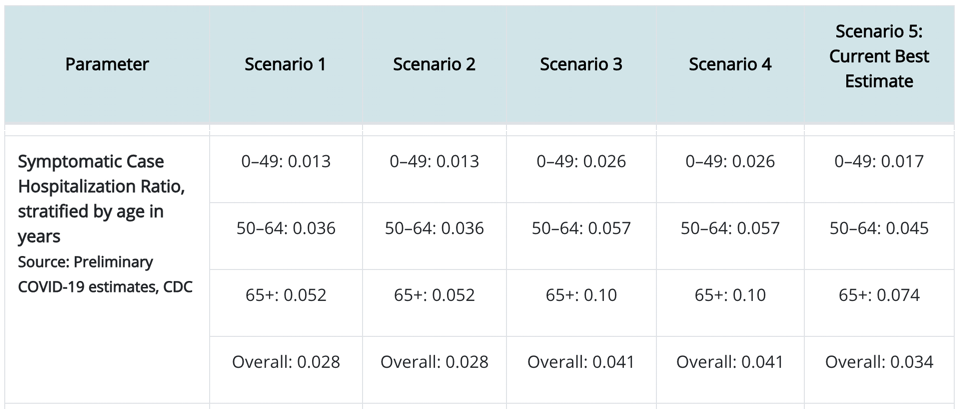
CDC estimates for symptomatic case hospitalization ratio for COVID-19
Focusing on Scenario 5’s “Overall” estimate, we see that each person who shows symptoms will have a 3.4% chance of being hospitalized. So that means we can estimate that for the population of 325M people in the USA, the 127M people we calculated above to show symptoms, 3.4% of them will have to be hospitalized, meaning that COVID-19 contribute 4.318M patients to hospitals in the USA (103M COVID-19 hospital patients worldwide). The question is whether we have enough hospital beds in the USA to accommodate these 4.318M people all at once. If we do not, then those that would have otherwise recovered will have to suffer through the disease without the support of medical professionals and medical technology. In other words, the case fatality rate for this subset of COVID-19 symptomatic individuals turned away from hospitals may rise to much higher than the 0.4% mentioned above. So this is really the essence of the movement to flatten the curve(e.g., by wearing masks and social distancing to reduce the effective contact rate). Even if it is impossible to avoid the 508,000 deaths predicted above, if infections can be spread out over a long amount of time, we can help to ensure that at any instant there will be enough hospital beds. Furthermore, if we stretch out the infection curve far enough, we may develop a vaccine within the curve’s duration. Vaccinations are a game changer because they provide a quick shortcut (that is hopefully much safer than a full-blown infection) to herd immunity.
But if we wanted to reduce that 508,000 without a vaccine, how would we do it? Remember that I said that R0 (a parameter of infection spread) is determined in part by the rate that an infectious individual contacts other individuals in the population. If we can devise long-term behavioral or technological methods to reduce this contact rate (beyond temporary inconveniences, such as wearing masks), then we can change R0 for COVID-19 for good (or at least for a sufficiently long time), thereby meaning that our endemic equilibrium (“herd immunity”) will occur with a much higher number of people who avoid infection (and even vaccination) entirely. How do we do that? Here are three potentially powerful ways.
We can remove hand shaking and other similar kinds of contact as a greeting (thereby bringing the baseline contact rate for every individual in the population to a much lower level than it was before COVID-19).
We can develop rapid, highly available, and frequent testing protocols that can quickly identify infected individuals so that they can be isolated (thereby bringing their personal contact rate much lower than others).
We can develop sophisticated contact-tracing techniques that can further identify potentially infected individuals so that they can be isolated (thereby bringing their personal contact rate much lower than others).
These behavioral and technological changes can actually improve our long-term COVID-19 outcome even if a vaccine is not developed. So it may not be inevitable that hundreds of thousands of more people have to die (at the time of this writing, over 110,000 people in the USA had death certificates that indicated COVID-19 as a cause of death).
Medical professionals can develop vaccines, researchers can develop novel technologies, and we can all alter our behaviors. Unfortunately, there are additional challenges in the near future that will make all of this even more urgent. In particular, we are facing a flu season ahead of us. Individuals who contract COVID-19 and the seasonal flu simultaneously may be in an untenable situation. Additionally, the medical system will face demands not only from COVID-19 but from those with the flu (but possibly not COVID-19) who also need hospitalization. Normally the medical system would have enough capacity to serve the seasonal flu population (although there are still seasonal flu deaths every year, just not as much as COVID-19). However, if the medical system has to face flu and COVID-19 along with baseline demands and any other emergent demands (other pandemics, etc.), then that will put our society as a whole in an untenable situation. The flu shot may be especially important to encourage this season.
Of course, there are many other interesting figures in that CDC report that we could further analyze that relate to how long the average COVID-19 hospital patient takes to recover, which would help us figure out more quantitative details about the amount of each of the kinds of possible actions discussed above will be necessary to prevent hospitals reaching capacity. For now, I will leave that analysis as an exercise for the reader. In the meanwhile, get some rest, stay safe, and stay healthy!
A silver lining of COVID-19 is that amazing conferences have become far easier and far cheaper to attend. For interdisciplinary researchers, you can now dip your toe into venues that you might not otherwise be able to justify spending the resources on. So it is a great time to branch out!
As an example, there are FOUR virtual Animal Behavior conferences that will be taking place soon this summer or early fall. They are free or nearly free (at least for students), and all of them are still accepting talk/poster abstracts at the time of this posting. If you are doing empirical or theoretical work in animal behavior and would normally present your work at a more methods-based conference, this is a great opportunity to get feedback from the larger behavior community. If you are not currently directly researching behavior, you might really enjoy just hearing reports of great, state-of-the-art research into animal behavior.
My background is in engineering, and I have found that animal behavior conferences to be the most educational and useful in generating bio-inspiration for me. These conferences showcase how animals interact with each other and the world around them in potentially adaptive ways. Plus, it's a great showcase of natural history for those who don't feel like they are naturally naturalists!
So check these out. And this is probably not an exhaustive list!
")
















")